历时两个月,终于初步完成一个SAS代码自动生成软件
自去年转到临床试验统计编程团队,我一直在思考如何提高效率(如何偷懒😜)。其中一个工作就是解决如何撰写数据集的说明文件(SPEC)更快速更标准,为此我开发了SPEC制作工具。这个工具可以引用标准或者历史的信息库,同时也可以导入EDC说明书信息,通过预设的各种可选项和便捷输入方式,使得使用者能够快速输出一个能用Pinnacle21进行define.xml转换的excel版SPEC文件,软件所有预想设计功能已经在5月底完成。
到这儿就够了吗?SPEC的作用是指导数据集的代码如何编写,于是我想让这个工具打通到底,在现有软件架构和功能的基础上,再设计一套通过快速配置,来生成各数据集的SAS代码。实现这套工具能覆盖统计编程程序员的全流程工作。在肝了2个多月之后,我终于完成了这一设想的主体功能,今天阶段性的记录下。
软件架构所用主要包
软件不是在线服务,但是使用场景是一个团队成员都能访问的远程桌面上。所以也算是一个平台软件,有账户密码的设计。使用Electron框架构建GUI软件,使用包含在软件内的sqlite数据库。前端使用Vue,后端使用Python。Python后端主要使用的包有SqlAlchemy、Pandas、Jinja等。
主要设计思路
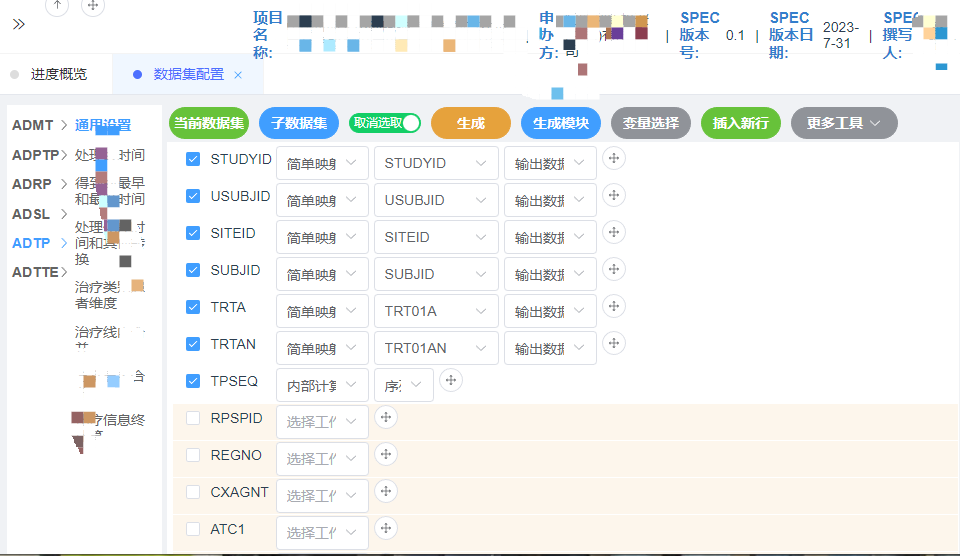
按照每个数据集、每个数据集内子数据集、每个子数据集的每个变量大概3级的维度进行分别配置。配置界面获得数据集SPEC配置的变量名、标签、类型、长度信息。也可以引用SPEC中的选项组。每个数据集的配置通过一系列子集完成,这些子集之间通过纵向或者横向组合,最后和基础子集组合后,形成最终输出的数据集。
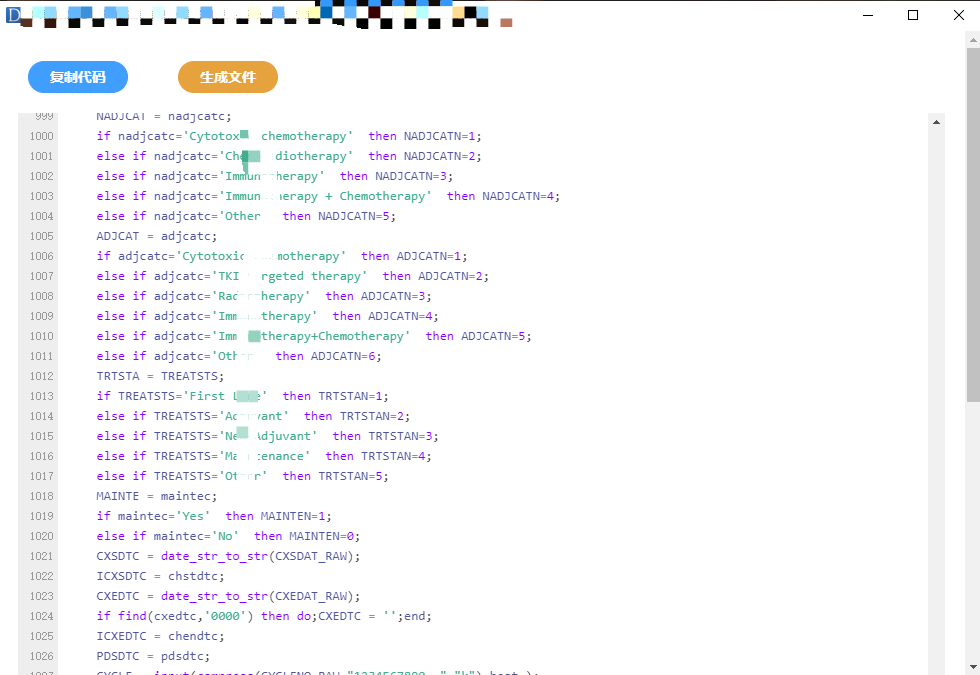
每个子集还按照不同类型分类,主要分为普通和降维型数据集,不同类型的数据集其变量配置的选项不一致,也会影响最后输出的模板。每个变量的配置按照直接引用、直接映射等分为不同类型,子数据集中也可以加减变量。配置完成后,最后经过后台程序整理,输出到Jinja模板中,由Jinja完成最终的代码渲染。
实际操作过程
我是边用实际项目进行配置边开发,根据实际项目需要来完成各种功能。最后用了两个项目完成了主体功能开发。通过配置来实现完整数据集的代码,这样的效果在使用工具的初期让我非常有成就感,产品的设想到落地初期是最让人激动和上头的阶段。到了后面一个月则是不断的加入新功能和解决各种bug。期间主要的耗时步骤还是生成代码后,沾到SAS程序里运行后生成结果和已有数据集进行对比,不断解决工具错误、配置缺失和项目规则理解错误的过程。
实现效果
- 最终实现了通过工具相对快速的配置,来生成一篇完整的数据集SAS代码,效果图如下:
1692931059011_3C025A51-06D4-4e28-B6DF-14878D5E206C.png
1692931123864_73067573-5143-46c3-A550-B31E8D28370B.png
后续工作
后续这个工具还要不断使用项目进行实践检验,和不断优化,证明它的价值。另外就是另一项激动人心的组件,TFL的配置。经过我的初步设想,复杂性要比数据集的配置更高,除了数据集的配置之外还需要很多样式设计、预设统计方法、Format设计等组件。